Introduction
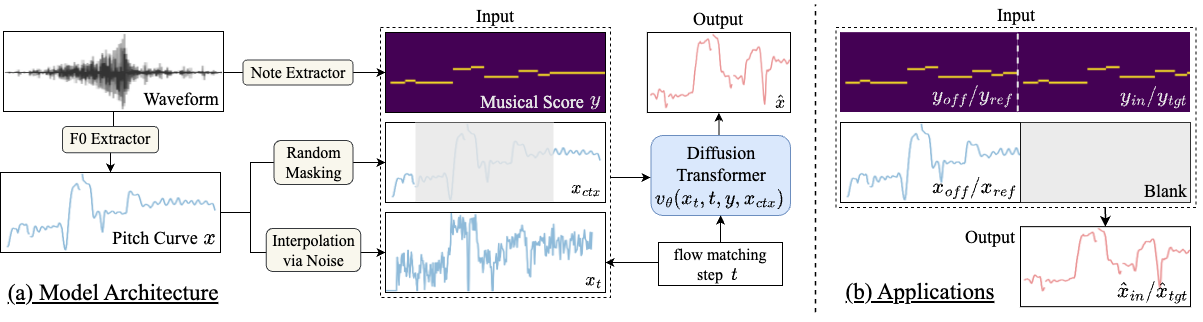
In this paper, we propose StylePitcher, the first general-purpose pitch curve generation model that learns to follow singing styles from reference audio. We formulate pitch generation as a masked infilling task: given surrounding pitch context and musical scores, StylePitcher learns to generate missing pitch segments that naturally continue the style patterns from context.
Once trained, StylePitcher serves as a plug-and-play module for diverse applications: enhancing pitch correction with style preservation, enabling style transfer in SVS systems, and improving expressiveness in SVC.
Generation Examples
We present audio examples from baselines and our methods in this section, including following applications:
- Automatic Pitch Correction
- Zero-shot Singing Voice Synthesis with Style Transfer
- Style-informed Singing Voice Conversion
Automatic Pitch Correction (APC)
Given a detuned singing voice (Off-key Singing) and a target note sequence (Target Notes), APC aims to generate an in-tune pitch contour that aligns with the target notes while preserving the singer’s original style for correction. We compare our methods, i.e., StylePitcher and StylePitcher (w/o smooth), with Diff-Pitcher.
| Off-key Singing | Target Notes | Diff-Pitcher | StylePitcher | StylePitcher (w/o smooth) |
|---|---|---|---|---|
Zero-shot Singing Voice Synthesis (SVS) with Style Transfer
Given target lyrics, musical score and a reference singing voice, style transfer for SVS aims to synthesize vocals that match the target content while resembling the singing styles of the reference. In the following examples, the singers in the reference audio have never been seen by the model during training, i.e., a zero-shot setting. We compare our methods, i.e., StylePitcher and StylePitcher (w/o smooth), with StyleSinger. All the methods support both parallel and non-parallel style transfer.
Parallel Style Transfer
In the parallel style transfer setting, the content of the reference singing voice is the same as the target lyrics and musical scores. Thus, the Reference audio here provides both the singing content (lyrics and musical scores) and the singing styles for re-synthesis.
| Reference | StyleSinger | StylePitcher | StylePitcher (w/o smooth) |
|---|---|---|---|
Non-Parallel Style Transfer
In the non-parallel style transfer setting, the content of the Reference singing voice differs from the target lyrics and notes.
Example 1
- Target lyrics: 离别没说再见
你是否心酸 - Target Phoneme: l i b ie m ei ei sh uo z ai j ian
n i sh i f ou x in s uan uan - Target Notes: 60 60 58 58 59 59 60 63 63 63 63 58 58 0 55 55 55 55 56 56 58 58 59 59 60
| Reference | StyleSinger | StylePitcher | StylePitcher (w/o smooth) |
|---|---|---|---|
Example 2
- Target lyrics: 无法遗忘
- Target Phoneme: u u f a a i i i uang uang uang
- Target Notes: 61 62 64 64 66 72 73 74 72 73 70
| Reference | StyleSinger | StylePitcher | StylePitcher (w/o smooth) |
|---|---|---|---|
Style-informed Singing Voice Conversion (SVC)
While most existing SVC methods use the unchanged F0 from the target audio to generate vocals with the reference singer’s timbre, StylePitcher can modify the F0 to also capture the singing styles of the target singer. In the following examples, Target audio provides the singing content, and Reference audio indicates the timbre and styles to convert. We compare our methods, i.e., StylePitcher and StylePitcher (w/o smooth), with In-house SVC.
| Target | Reference | In-house SVC | StylePitcher | StylePitcher (w/o smooth) |
|---|---|---|---|---|